Across the global corporations, I advise, in financial services, healthcare, retail and the public sector, the same crisis surfaces in leadership meetings. Executives approved a bold AI roadmap. Cloud spending climbed 40, 50, even 70 percent. And yet the AI workloads that made perfect sense in the boardroom presentation now stall, overshoot their budgets or collapse under production load before they reach real users.
I am writing this just after the spring 2026 conference season, and the signal from Google Cloud Next, Microsoft Build, and a run of AWS summits only sharpens the point. Over the past several weeks the industry shipped, in production form, the infrastructure to run and govern AI at scale. What most enterprises still lack is the operating model to decide how to use it.
The problem is not the AI models. The models work. The problem is that organizations built their AI ambitions on cloud strategies designed for a world that no longer exists: strategies built for SaaS applications, predictable traffic and linear cost curves. AI workloads break all three assumptions at once.
Why AI breaks traditional cloud assumptions
For a decade, cloud-first served enterprises well. It delivered elasticity, reduced capital expenditure and democratized access to compute, because enterprise workloads were predictable: web applications, ERP systems, databases and analytics pipelines that scaled smoothly and billed in ways finance could model on a spreadsheet. GenAI and agentic AI change every one of those assumptions at once.
When organizations move AI into production, real inference, retrieval pipelines, vector search and real-time decisioning, the cloud equation breaks in at least five ways:
- Training clusters demand power densities far above standard compute.
- Inference needs millisecond latency that network geography can defeat.
- Vector databases generate cost spikes invisible in standard billing.
- Agentic workloads chain hundreds of tool calls with cascading dependencies.
- And data-sovereignty rules constrain where any of them can run.
In short, what works at the platform level fails at the workload level.
The costs are the first thing to surprise leaders, because they hide. CloudZero’s analysis and the FinOps teams I work with put it plainly: AI spend surfaces as generic compute, storage and instance line items, rarely labeled “AI.” Three layers drive most of the waste:
- The most visible is LLM API cost, where stateless calls re-send the full conversation history on every request, so a deployment with a couple hundred users can burn many times the token budget in the business case.
- The biggest is idle GPU: teams’ provision for peak and then run at 10 to 20 percent utilization, and most miss their AI cost forecasts by more than a quarter.
- The most underestimated is the vector database and retrieval layer, where storage I/O, query volume and embedding refresh appear nowhere labeled AI until the bill arrives.
The dimensions leaders underweight resilience and control
Cost and latency dominate the conversation. Two dimensions rarely get the same rigor until something breaks:
- Resilience, whether an AI-dependent system can survive failure, degrade gracefully and recover predictably.
- Control, who can observe, halt and audit it.
AI introduces failure modes that traditional architecture never faced: GPU single points of failure under revenue-critical inference, agentic pipelines that fail mid-execution with no rollback, and models that degrade silently from drift or throttling.
I see the pattern repeated across industries. Organizations design resilience for their traditional applications, then deploy AI on top without asking whether the same guarantees hold. In one global financial services firm I advise, a real-time credit-decisioning model running on a single cloud region took a 47-minute outage during a regional availability event. The halted loan approvals cost more than the system’s entire annual infrastructure budget, and the resilience rework that followed cost several times what designing it in from the start would have. The leaders who avoid this should ask four questions before go-live:
- What happens when the network fails?
- What happens when the model degrades?
- What happens when an agent executes only halfway?
- Who holds the authority to halt and audit?
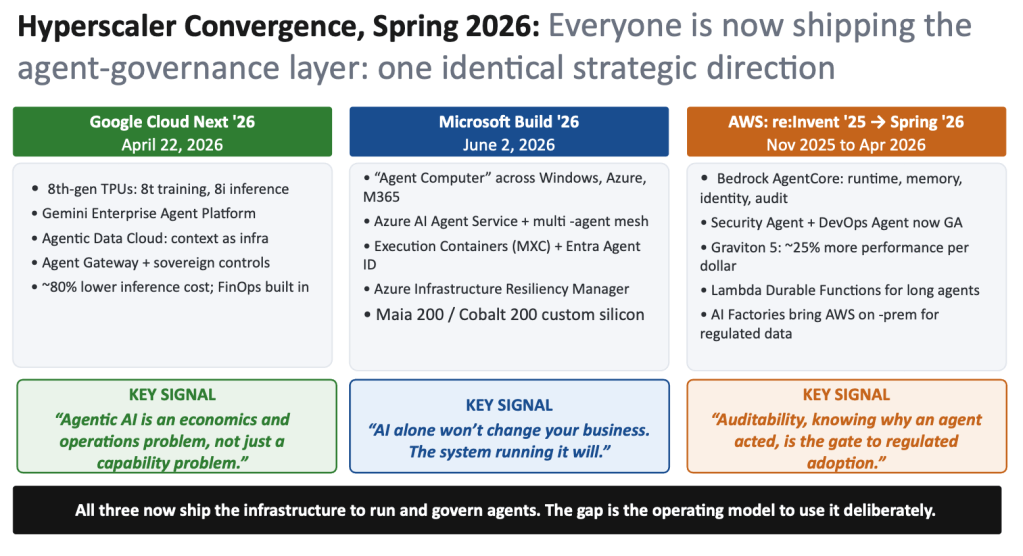
What the cloud providers signaled this spring
The major providers are on track to spend close to $700 billion on AI infrastructure in 2026, roughly three and a half times the 2024 level. Their announcements are strategic signals, not just features. Last year they converged on one message: enterprises cannot run everything in public cloud, so all three built ways to bring their infrastructure into your data center and your sovereign environment. This year the signal advanced a step. They stopped talking about where workloads run and started shipping the layer that governs what agents are allowed to do: identity, containment, auditability and rollback.
Microsoft introduced an “Agent Computer” model with execution containers and machine identity for agents. AWS built Amazon Bedrock AgentCore around runtime, memory, identity and auditability. Google shipped an agent gateway and sovereign controls for cross-cloud traffic. As Bain observed, agentic AI is now an economics and operations problem, not just a capability problem. The through-line, captured by Microsoft’s own framing, is that AI alone will not change your business; the system running it will. McKinsey’s read is consistent: workloads are becoming more distributed, specialized and operationally demanding, which forces more deliberate infrastructure decisions.
Vipin Jain
From platform choice to placement decision
The failure I document most often is not a technology failure; it is a governance failure. Most enterprises lack a clear, repeatable way to decide what runs where, under what conditions and with what tradeoffs. Platform teams make that call informally, under deadline pressure and repeat it hundreds of times as new use cases launch. Workloads then accumulate in public cloud by default, not by design and 30 to 50 percent cost overruns follow, not because public cloud was the wrong choice but because no deliberate choice was ever made.
In one global manufacturer I advise, a predictive-maintenance model went live on public cloud and performed exactly as validated in staging. But real-time inference on the factory floor ran at 80 to 120 milliseconds across the WAN, when the machine-control system needed under ten. Moving the model to edge nodes fixed the latency, but the company lost most of a quarter of the cost, rework and delayed benefits, and the line had run for weeks on stale recommendations: a control failure that could have caused a safety event. The fix was never more AI talent. It was a structured placement decision at the start, weighing six dimensions:
- Latency: real-time (under 10 ms, edge or on-prem), interactive (50 to 500 ms, cloud) or batch.
- Cost and TCO: token spend, GPU utilization, vector-database queries, egress and unit economics per workload.
- Resilience: failover architecture, degraded-mode behavior, recovery SLA and rollback policy.
- Control: observability, audit trails, governance authority and the ability to halt or reverse.
- Data sensitivity: sovereignty requirements, privacy and compliance rules, and IP protection.
- Integration: legacy system dependencies, pipeline complexity and data-residency constraints.
Run consistently, those dimensions produce a placement pattern like this:
| Workload | Latency | Cost predictability | Data sovereignty | Recommended path |
| Customer-facing chatbot | 200-500 ms | Medium | Low risk | Public cloud, reserved instances |
| Real-time fraud detection | Under 10 ms | Medium | High | On-prem or sovereign private cloud |
| Clinical decision support | 100-300 ms | Predictable | Critical | Sovereign cloud or dedicated VPC |
| Demand forecasting (batch) | Hours | High | Low risk | Spot instances or scheduled cloud |
| Factory-floor vision AI | Under 5 ms | Predictable | Medium | Edge node (Azure Local, AWS on-prem) |
| Internal knowledge assistant | 1-3 sec | Variable tokens | High (IP risk) | Private cloud with on-prem retrieval |
This is no longer optional. Cloudian’s 2026 enterprise AI infrastructure survey found that 79 percent of enterprises have already moved AI workloads out of public cloud, and 93 percent are repatriating or actively evaluating it, driven by data sovereignty, cost overruns and real-time performance. Repatriation is now the norm, not the exception.
The agentic layer makes discipline urgent. An agent chains 20 to 100 tool calls, each with its own latency, cost and failure mode, so the governance model that works for a chatbot does not work for an autonomous agent approving procurement or onboarding a customer. This spring the providers shipped production infrastructure for exactly this, yet Deloitte’s 2026 survey of more than 3,000 leaders finds only about one in five companies has a mature governance model for autonomous agents. The platforms solved the mechanism. Most enterprises have not yet written the policy.
What the leaders do differently
The organizations extracting compounding value from AI, not just running experiments, share one discipline: they treat workload placement as a repeatable process, and they build resilience and control in from the start rather than after the first production incident. In practice, they do five things:
- Classify every use case at intake across the six dimensions, before any infrastructure is provisioned.
- Separate AI budget lines for experiments, production inference and training, so cost is governable.
- Treat unit economics, cost per inference, per query and per agent run, as engineering KPIs, not month-end surprises.
- Define repatriation triggers in advance, typically 12 to 18 months of stable volume.
- Write an explicit resilience contract, and agentic observability and rollback rules, before scaling.
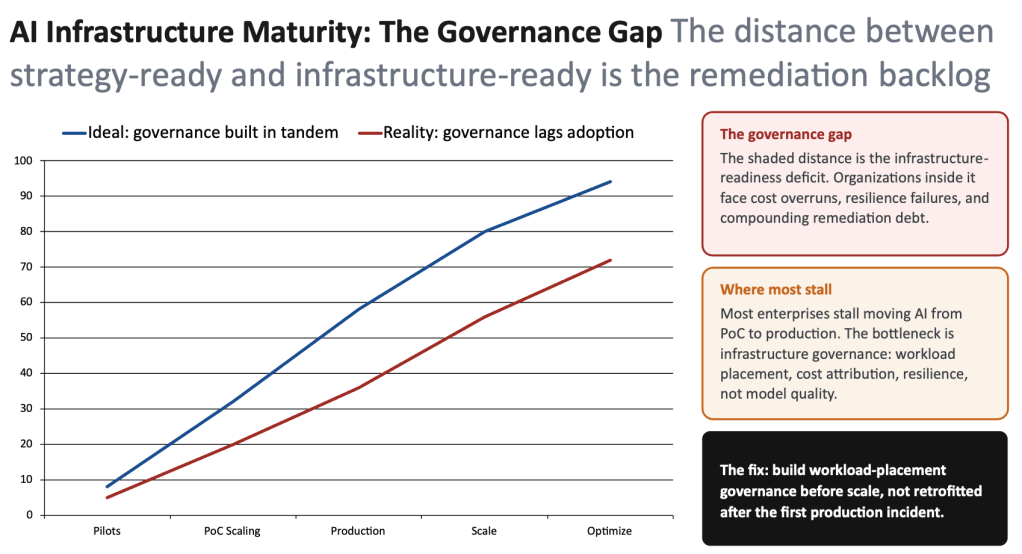
The gap between strategy-ready and infrastructure-ready is the remediation backlog, and most enterprises stall moving from proof of concept to production for exactly this reason. Deloitte’s tech-trends analysis frames the same shift as the move to inference economics: the bottleneck is infrastructure governance, not model capability.
Vipin Jain
For CIOs, a 90-day agenda. Five actions separate the leaders from those managing infrastructure crises:
- Audit every AI workload in production across latency, cost, sovereignty, volume, resilience, control and integration.
- Separate AI infrastructure budget lines so each workload type is attributable and governable.
- Define unit economics by workload and review them as engineering KPIs.
- Set a quantitative repatriation evaluation trigger.
- Define observability, cost attribution and rollback policy before scaling agents.
The strategic reframe
The organizations making real progress on AI are not distinguished by the sophistication of their models or the size of their cloud contracts. One discipline sets them apart: a clear, repeatable way to decide what runs where, under what conditions, with what tradeoffs and what happens when something fails. That discipline is not an IT problem. It is a strategic capability that requires CIO ownership, CFO alignment and executive accountability.
This spring the cloud providers handed enterprises the infrastructure to run and govern AI, and agents, at every tier of the architecture. The gap is no longer supply. It is the operating model to use deliberately. The companies building that model now build the operating foundation for AI at scale. Everyone else builds a remediation backlog. The infrastructure decisions you make in the next 12 months will decide which of those two you become.
This article was made possible by our partnership with the IASA Chief Architect Forum. The CAF’s purpose is to test, challenge and support the art and science of Business Technology Architecture and its evolution over time as well as grow the influence and leadership of chief architects both inside and outside the profession. The CAF is a leadership community of the IASA, the leading non-profit professional association for business technology architects.
This article is published as part of the Foundry Expert Contributor Network.
Want to join?
Read More from This Article: AI is exposing the real limits of enterprise cloud strategy
Source: News