The morning of Monday, Oct 20, 2025, I went to my healthcare provider’s portal to pay a bill. This was my experience:
Jim Wilt
Upon calling my provider to pay over the phone, they were unable to take my payment as their internal systems were also down, leaving us customers hanging with no direction on how to proceed.
My healthcare provider’s SaaS was completely functional; however, their integrated payment vendor, which is reliant on AWS infrastructure, apparently has ineffective redundancies. So, the 10/20/2025 AWS outage resulted in a most unfortunate experience for any customer or employee hoping to utilize this important capability while hindering my healthcare organization from receiving revenue.
Who is to blame? AWS? The payment vendor? Ultimately, my healthcare provider is responsible for their customers’ (and employees’) inability to interact with their services. A cloud outage is not in the same acts-of-nature class as hurricanes, earthquakes, tornadoes, etc., but we do treat them as such and that is simply wrong because these outages can be mitigated.
This is a clear and far too common industry-wide epidemic: poor adoption and execution of cloud computing resilience, resulting in unreliable critical services to both customers and employees.
As reported directly by AWS’ Summary of the Amazon DynamoDB Service Disruption in Northern Virginia (US-EAST-1) Region, a latent race condition in DynamoDB’s DNS management system led to an empty DNS record for the US-EAST regional endpoint, causing resolution failures affecting both customer and internal AWS service connections. This adversely affected the following services: Lambda, ECS, EKS, Fargate, Amazon Connect, STS, IAM Console Sign-In and Redshift.
On 10/29/2024, Microsoft 365 (m365.cloud.microsoft or portal.office.com) experienced an outage due to the rollout of an impacting code change. This affected Microsoft 365 admin center, Entra, Purview, Defender, Power Apps, Intune and add-ins & network connectivity in Outlook. This is all documented by Microsoft in Users may have experienced issues when accessing m365.cloud.microsoft or portal.office.com.
Both of these recent outages required vendors to halt automated processes and manually navigate recovery to bring affected systems back to an operational state. Let’s face it: Cloud providers are not magical and are subject to the same recovery patterns as any enterprise.
Outages are a reality of any system or platform and affect literally every organization. Hence:
Your cloud provider is a single point of failure!
Corporate infrastructure strategies vary from total dependence on provider vendors to actively taking ownership and architecting necessary redundancies for critical systems. When underlying provider outages occur, it is often a catalyst to revisit enterprise resilience strategy, even if you are not directly affected.
When examining an enterprise’s fault-tolerant architectures (which rarely even exist), it may be a good time to instead consider fault avoidance architectures. The latter kicks in when bad happens and the former actively monitors triggers to avoid bad.
This type of introspective examination is too often overlooked, as it is far easier for enterprises to fall into believing the many myths that govern their IT strategy and operations, especially when it comes to Cloud.
Unpacking the myths
Myth #1 – A single cloud provider reduces complexity
Vendors will place every kind of study and incentive in front of enterprise leadership to back the fallacy that locking into their platform is in the best interests of their company. Let’s be clear: It is always in the best interests of the vendor. This concept is then passed down from leadership to engineers who are encouraged to believe what their leadership tells them, and we get into a situation where thousands upon thousands of companies are under the control of a single vendor. Scary, right?
When it comes to multi-zonal resilience, app-cross-region resilience, blast-radius reduction, and resilient app patterns, there is additional complexity. Knowing that these approaches have dependencies on complex fine-tuned cloud infrastructures means there is no easy button.
Myth #2 – Cloud platform component defaults are generally a good starting point
Relying on easy-button best practices is what gets enterprises into trouble. The responsibility of an IT cloud infrastructure team is to work with solution architects and engineers to fine-tune their designs to optimize efficiencies, resilience and performance while controlling costs. Cloud vendor default configurations are necessary as they set a functional starting point, but they should never be trusted as a sound design. In fact, they can produce unnecessarily large loads on default regions when left unchecked. The AWS US-East-1 region is historically the most affected region when it comes to outages, and yet so many critical enterprise systems run exclusively in that region.
Vendor plug-and-play architectures must be scrutinized before going into production.
A responsible architecture governance practice should have a policy to avoid known outage-prone regions and single-point-of-failure configurations. These should be vetted in the architecture review board before ever going to production.
Myth #3 – My cloud provider/vendor will take care of me
Service level agreements (SLA) are paid out service credits tied to the cost of the affected service, not cash refunds. They generally start at 10% of service charges, never resulting losses. Your enterprise will literally get pennies back on dollars lost.
The July 2024 CloudStrike outage cost CloudStrike around $75M + $60M they paid out in service credits. This pales an order of magnitude when compared to just one customer, Delta Airlines, which lost $500M net. Parametrix Insurance’s detailed analysis estimates the total direct financial loss facing the US Fortune 500 companies is $5.4B. CloudStrike literally paid pennies on the dollar for their error, so an enterprise’s reliance on a vendor must be managed knowing this reality.
The 11/18/2025 Cloudflare outage, with its 20% hold on global web traffic, equally affected hundreds of millions of accounts, including major systems like X (Twitter), OpenAI/ChatGPT, Google’s Gemini, Perplexity AI, Spotify, Canva and even all three cloud providers. This heightens how a single vendor/platform dependency is a real threat to business continuity.
Enterprises must protect themselves because their vendors won’t.
Future purchase and contract negotiations should pivot toward SLA penalties that are based on enterprise losses over enterprise service costs. Unfortunately, this will drive service costs higher, but it builds in better financial protection when reliant on systems outside of your control.
Myth #4 – Multi-cloud is too expensive and too demanding
To mitigate the impact of regional cloud outages, enterprises that adopt multi-cloud architectures that prioritize resilience, portability, and failover orchestration find additional benefits when they are implemented with a mindset of fault avoidance and cost/performance optimization. This means multiple triggers govern where workloads run, resulting in optimal efficiencies.
This needs to be a priority effort backed by the C-Suite and requires a culture shift to succeed; hence, multi-cloud deployments are exceedingly rare. Still, those who have done this reap benefits well beyond resilience (e.g., large orgs like Walmart, Goldman Sachs, General Electric and BMW as well as SMBs like FirstDigital, Visma and Assorted Data Protection).
The NIST Cloud Federation Reference Architecture (NIST Special Publication 500-332) is a great document to establish a baseline grounding of these concepts.
- Active-active resilience is a pattern for mission-critical apps (e.g., financial trading, healthcare, e-commerce checkout). It maximizes resilience and availability, but at a higher cost due to duplicated infrastructure and complex synchronization. This pattern lends itself best toward fault avoidance with all the goodness of proactive efficiency and optimization triggers.
- Active-passive failover is a pattern where a primary cloud handles all traffic, and a secondary cloud is on standby. It provides disaster recovery without the full cost of active-active, but will introduce some downtime and requires a robust replication strategy. It clearly is only a fault-tolerant approach.
- Cloud bursting is a pattern where applications run primarily in one cloud but “burst” into another during demand spikes, providing elastic scalability without over-provisioning. It can also provide a good degree of fault tolerance.
- Workload partitioning (best-of-breed placement) is a pattern where different workloads are assigned to the cloud provider best suited for them. It greatly optimizes performance, compliance, and cost by leveraging provider strengths, but will not be fully fault-tolerant.
Myth #5 – Cloud has failed. It’s time to get out
This is a recurring theme each time there is a major cloud outage, often tied equally to a cost comparison between on-premises vs. cloud (yes, cloud almost always costs more). The reality is that while there is true value to cloud in the overall infrastructure strategy, there also is value in prioritizing an investment in infrastructure choices, leveraging sensible hybrid strategies. Two effective strategic architectures are based on edge and Kubernetes. Edge reduces blast radius, while Kubernetes provides portable resilience across providers. Both are recommended when aligned with workload architecture and operational maturity.
- Edge-integrated resilience extends workloads to the edge while maintaining synchronization with central clouds. Local edge nodes can continue operations even if cloud connectivity is disrupted, then reconcile state once reconnected. In addition to adding a moderate level of resiliency, it also benefits from ultra-low latency for real-time processing (e.g., IoT, manufacturing robotics, autonomous vehicles). This approach is often found in factory, retail store, and branch office use cases.
- Kubernetes-orchestrated resilience is a cloud-agnostic orchestration layer that can be leveraged locally and across multiple providers. In addition to a prominent level of resilience, this type of service mesh (e.g., Istio, Linkerd) adds traffic routing and failover capabilities that reduce vendor lock-in. Overall, it is a foundational enabler for multi-cloud, giving enterprises a consistent control plane across providers and on-premises.
Calls to action
There are two major enterprise IT leadership bias camps: Build and Buy. Both play a factor in every enterprise.
The reference architecture patterns shared above address Build bias workloads, which include integrations with Buy workloads.
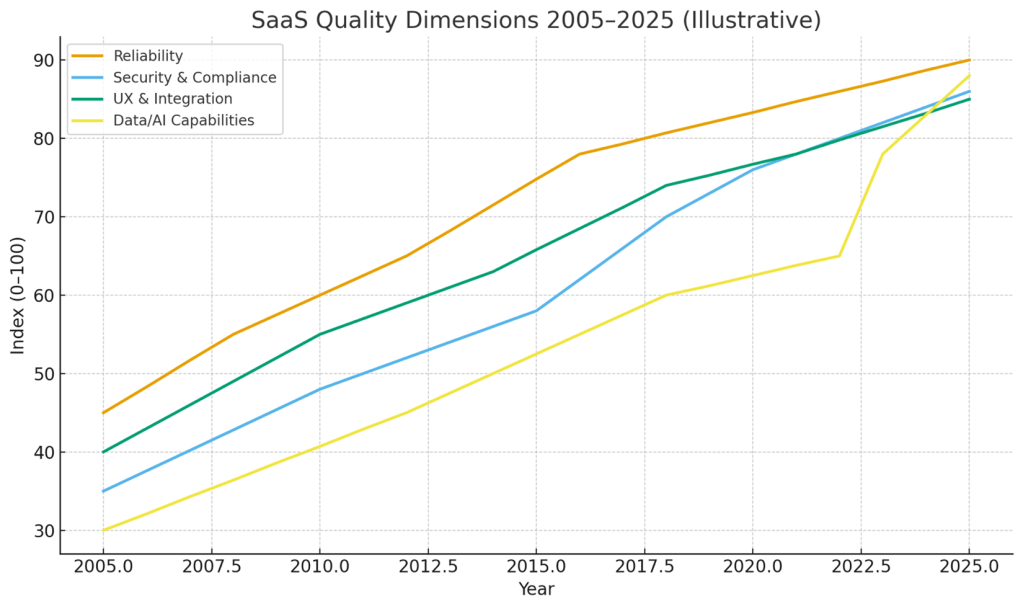
Buy bias workloads are too often subject to vendor-defined SLAs discussed above, which are terribly limiting to 10-100% credits for charges based on the duration of an outage as penalties. Realistically, that really is not going to change; however, SaaS quality over the past 20 years has increased substantially:
Jim Wilt
This becomes the new bar and offers a great measure an enterprise can leverage for both themself and their vendors:
The 1-9 Challenge: Every SaaS vendor, integrator and internal enterprise solution should provide one “9” better than their underlying individual hosting platforms alone.
For example, when each cloud vendor provides a 99.9% SLA for a given service, leveraging an active-active multi-cloud architecture raises that SLA well beyond 99.99%.
Take control of your critical services first and leverage these patterns as a baseline for net-new initiatives moving forward, making high resilience your new norm.
Bottom line: the enterprise is always responsible for its own resiliency. It’s time to own this and take control!
This article was made possible by our partnership with the IASA Chief Architect Forum. The CAF’s purpose is to test, challenge and support the art and science of Business Technology Architecture and its evolution over time as well as grow the influence and leadership of chief architects both inside and outside the profession. The CAF is a leadership community of the IASA, the leading non-profit professional association for business technology architects.
This article is published as part of the Foundry Expert Contributor Network.
Want to join?
Read More from This Article: Your cloud provider is a single point of failure
Source: News