
Large language models (LLMs) have rapidly become a cornerstone of modern enterprise operations, powering everything from customer support chatbots to advanced analytics platforms. While these models offer unparalleled capabilities, they also pose significant challenges for organizations—mainly their size, resource demands and sometimes unpredictable behaviour. Enterprises often grapple with high operational costs, latency issues and the risk of generating inaccurate or irrelevant outputs (commonly referred to as hallucinations). To truly harness the potential of LLMs, businesses need practical strategies to optimise these models for efficiency, reliability and accuracy. One key technique that has gained traction is model distillation.
Understanding model distillation
Model distillation is a method used to transfer the knowledge and capabilities of a large, complex model (the teacher) into a smaller, more efficient model (the student). The goal is to retain the teacher’s performance while making the student model lighter, faster and less resource-intensive. Distillation works by training the student to mimic the outputs or internal representations of the teacher, essentially “distilling” the essence of the larger model into a compact form.
Why is this important for enterprises? Running massive LLMs can be costly and slow, especially in environments where quick responses and scalability are crucial. Model distillation provides a means to deploy powerful AI solutions without the heavy infrastructure burden, making it a practical choice for businesses seeking to strike a balance between performance and efficiency.
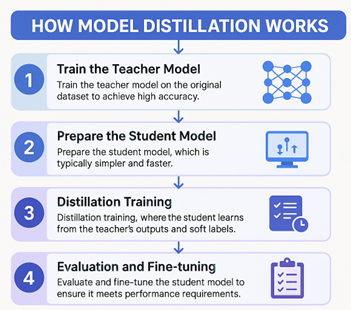
How model distillation works
- Train the trainer/teacher model: Begin with a large, pre-trained language model that performs well on your target tasks.
- Prepare the student model: Design a smaller, more efficient model architecture that will learn from the teacher.
Magesh Kasthuri
- Distillation training: The student is trained using the teacher’s outputs or “soft labels,” learning to replicate its behaviour as closely as possible.
- Evaluation and fine-tuning: Assess the student’s performance and, if necessary, fine-tune it to ensure it meets accuracy and reliability requirements.
Throughout this process, the student model becomes adept at handling enterprise tasks with far less computational overhead, making it ideal for real-time applications.
Model distillation in practice
Imagine a financial services company that uses an LLM to generate investment reports. The original model is highly accurate but slow and expensive to run. By applying model distillation, the company trains a smaller student model that produces nearly identical reports with a fraction of the resources. This distilled model can now deliver insights in real-time, enabling analysts to make faster decisions while cutting operational costs.
In another scenario, a healthcare provider deploys an LLM-based assistant to help doctors access patient information and medical guidelines. The full-scale model offers excellent recommendations but struggles with latency on edge devices. After distillation, the student model fits comfortably on hospital servers, providing instant responses and maintaining data privacy.
Industrial use cases: Real-time scenarios across sectors
- Financial services: Distilled models power fraud detection systems, delivering rapid alerts without draining computational resources.
- Healthcare: Hospitals use distilled LLMs for triaging patient queries and supporting clinical decisions at the point of care.
- Customer service: Call centres deploy compact chatbots trained via distillation to handle large volumes of queries efficiently.
- Retail: E-commerce platforms run product recommendation engines using distilled models to personalise shopping experiences in real time.
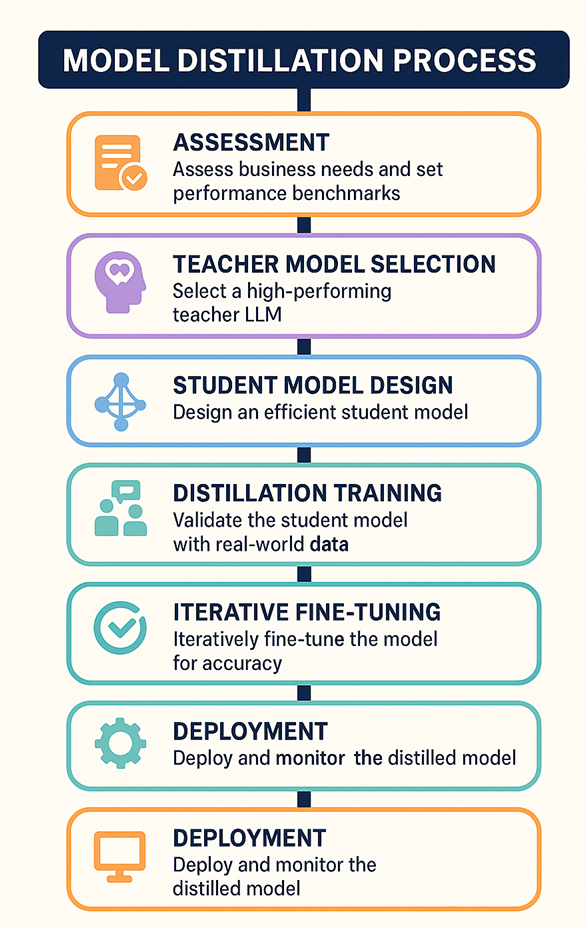
Framework for model distillation: Optimizing LLMs for enterprises
To systematically optimise LLMs for enterprise use, a robust framework for model distillation is essential. Here’s a stepwise approach designed for IT professionals:
- Assessment: Identify the target tasks and performance benchmarks required for your business operations.
- Teacher model selection: Choose a high-performing LLM as your teacher, ensuring it excels at your chosen tasks.
- Student model design: Architect a smaller model that can be trained efficiently while retaining core capabilities.
- Distillation training: Use the teacher’s outputs to guide the student, focusing on both output accuracy and internal representations.
Magesh Kasthuri
- Validation: Rigorously test the student model against real-world data to spot hallucinations and inaccuracies.
- Iterative fine-tuning: Continuously improve the student model by refining its training data and adjusting its architecture as needed.
- Deployment: Integrate the distilled model into your enterprise systems, monitoring performance and updating as required.
How the framework reduces hallucinations and improves accuracy
A key challenge with LLMs is their tendency to “hallucinate”—generating plausible-sounding but incorrect information. The distillation framework addresses this by incorporating validation steps that test the student model against curated datasets and real-world scenarios. By exposing the student to diverse data during training and fine-tuning, enterprises can reduce the risk of hallucinations and ensure outputs remain reliable. Furthermore, ongoing monitoring and iterative updates help maintain model accuracy as business needs evolve.
Practical considerations and implementation tips
- Customise training data: Use enterprise-specific datasets during distillation to align the model with your organizational context.
- Monitor model outputs: Regularly review the student’s responses to catch emerging issues early.
- Plan for scale: Design the distilled model architecture to support future growth and integration with other systems.
- Collaborate across teams: Involve domain experts during validation to ensure the model meets real-world requirements.
Benefits for large enterprises
For large organizations, model distillation offers several compelling advantages:
- Cost savings: Reduced computational demands lead to lower infrastructure and energy costs.
- Improved reliability: Streamlined models respond faster and are easier to maintain, ensuring consistent service.
- Scalability: Lightweight models can be deployed across multiple platforms and locations, supporting enterprise expansion.
- Enhanced accuracy: The framework’s focus on validation and fine-tuning helps minimise errors and hallucinations.
Conclusion
Model distillation stands out as a key technique for making large language models fit for enterprise operations. By transferring knowledge from complex models to efficient students, businesses can enjoy the best of both worlds—powerful AI capabilities without the heavy resource burden. As enterprises continue to adopt AI at scale, model distillation will play a pivotal role in ensuring solutions are cost-effective, reliable and tailored to real-world needs. IT professionals seeking to maximise the value of LLMs should consider integrating distillation frameworks into their optimization strategies, paving the way for smarter, more agile enterprise AI.
This article is published as part of the Foundry Expert Contributor Network.
Want to join?
Read More from This Article: How to optimize LLMs for enterprise success
Source: News