Generative AI has gone from research novelty to production necessity. Models like GPT-4, Claude, Gemini and Llama now power everything from customer support to developer tooling. Yet many leaders still describe these systems as “black boxes.”
The reality is far less mysterious. What powers every generative AI model is not magic, but architecture. Specifically, the transformer. Understanding this architecture helps leaders make smarter decisions about infrastructure costs, scaling and where AI can (and cannot) deliver value.
From sequences to systems that understand context
Before 2017, nearly every AI system that dealt with language relied on recurrent neural networks (RNNs) or their improved variant, LSTMs (long short-term memory networks). These architectures processed text sequentially, one token at a time, passing the output of one step into the next like a relay baton carrying memory through the sentence.
This design was intuitive but restrictive. Each word depended on the previous one, which meant training and inference couldn’t be parallelized. Processing a long paragraph required thousands of dependent steps, making RNNs inherently slow and memory intensive. They also struggled with long-range dependencies in which early information often got “faded” by the time the model reached the end of a sentence or paragraph, a problem known as the vanishing gradient.
Engineers tried to solve this by increasing memory capacity (via LSTMs and GRUs), adding gates and loops to preserve context, but these models still worked linearly. The result was a trade-off: accuracy or speed, but rarely both.
The transformer upended this paradigm. Instead of learning language as a sequence through time, it learned it as a network of relationships. Each token in a sentence can “see” every other token simultaneously, using attention to decide which relationships matter most. The model no longer relies on passing a single stream of memory step-by-step; it builds a complete context map in one shot.
This shift was more than a performance improvement; it was an architectural breakthrough. By enabling parallel computation across all tokens, transformers made it possible to train on massive datasets efficiently and capture dependencies across entire documents, not just sentences. In essence, it replaced memory with connectivity.
For engineering leaders, this was the moment machine learning architecture started to look like systems architecture which was distributed, scalable and optimized for context propagation instead of sequential control. It’s the same conceptual leap that turns a single-threaded process into a multi-core system: throughput increases, latency drops and coordination becomes the new design challenge.
Tokens, vectors and meaning
Think of a token as the smallest unit a model can process: a word, subworld or even punctuation. When you type “transformers power generative AI,” the model doesn’t see letters; it sees tokens such as [Transform], [ers], [power], [generative], [AI].
Each token is converted into a vector which is a list of numbers that encodes meaning and context. These vectors are how machines “think”. They represent ideas not as symbols but as positions in a high-dimensional space: words with similar meanings live close together.
The attention mechanism: How understanding emerges
Inside a transformer, attention is the mechanism that lets tokens talk to each other. The model compares every token’s query (what it’s looking for) with every other token’s key (what information it offers) to calculate a weight which is a measure of how relevant one token is to another. These weights are then used to blend information from all tokens into a new, context-aware representation called a value.
In simple terms: attention allows the model to focus dynamically. If the model reads “The cat sat on the mat because it was tired,” attention helps it learn that “it” refers to “the cat,” not “the mat.”
By doing this in parallel across thousands of tokens, transformers achieve context awareness at scale. That’s why GPT-4 can write multi-page essays coherently, it’s not remembering word by word, it’s reasoning over relationships between vectors in context.
Transformers at a glance
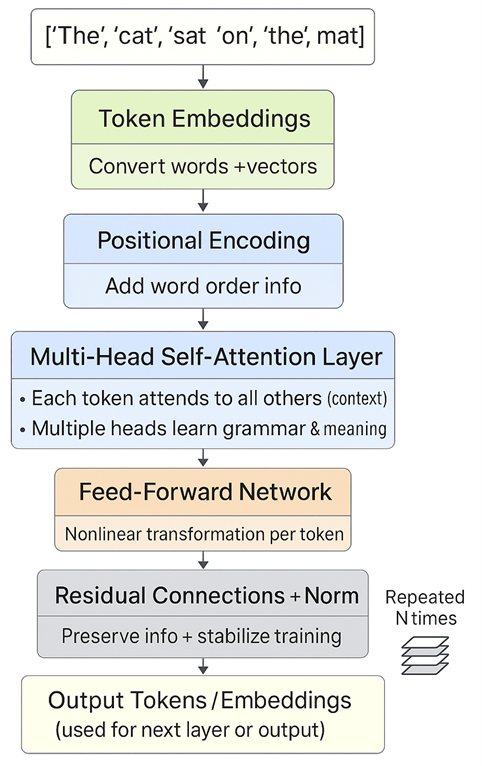
A transformer processes text in several structured steps, each designed to help the model move from understanding words to understanding meaning and relationships between them.
Ankush Dhar
The process begins with input tokens, where the sentence e.g. “The cat sat on the mat” is split into smaller units called tokens. Each token is then converted into a numerical form through Token Embeddings, which then translate words into high-dimensional vectors that capture semantic meaning (for example, “cat” is numerically closer to “dog” than to “mat”).
However, because word order matters in language, the model adds Positional Encoding which is a mathematical signal that injects information about each token’s position in the sequence. This allows the transformer to distinguish between “The cat sat on the mat” and “The mat sat on the cat.”
Next comes the multi-head self-attention layer, the heart of the transformer. Here, each token interacts with every other token in the sentence, learning which words matter most to one another. For instance, “cat” pays attention to “sat” and “mat” because they are contextually related. Multiple “heads” of attention learn different types of relationships simultaneously, some focusing on grammar, others on meaning or dependency.
Each token’s refined representation then passes through a feed-forward network, which applies nonlinear transformations independently to every token, helping the model combine and interpret information more deeply.
Afterward, residual connections and normalization ensure that useful information from earlier layers isn’t lost and that the training process remains stable and efficient. These mechanisms keep gradients flowing smoothly through the network and prevent degradation of learning across layers.
Finally, the processed representations emerge as output tokens or embeddings, which either serve as input to the next transformer layer or as the final contextualized output for prediction (like generating the next word).
This simple loop of attention, transformation, normalization is repeated dozens or even hundreds of times. Each layer adds nuance, letting the model move from recognizing words, to ideas, to reasoning patterns.
Scaling and serving: Where architecture meet cost
Transformers are powerful, but they’re also expensive. Training a model like GPT-4 requires thousands of GPUs and trillions of data tokens.
Leaders don’t need to know tensor math, but they do need to understand scaling trade-offs. Techniques like quantization (reducing numerical precision), model sharding (splitting across GPUs) and caching can cut serving costs by 30–50% with minimal accuracy loss.
The key insight: Architecture determines economics. Design choices in model serving directly impact latency, reliability and total cost of ownership.
Beyond text: One architecture, many domains
When transformers were first introduced in 2017, they revolutionized how machines understood language. But what makes the architecture truly remarkable is its universality. The same design that understands sentences can also understand images, audio and even video because at its core, a transformer doesn’t care about the data type. It just needs tokens and relationships.
In computer vision, vision transformers (ViT) replaced traditional convolutional neural networks by splitting an image into small patches (tokens) and analyzing how they relate through attention much like how words relate in a sentence.
In speech, architectures such as Conformer and Whisper applied the same self-attention principle to learn dependencies across time, improving transcription, translation and voice synthesis accuracy.
In multimodal AI, models like CLIP and GPT-4V combine text, images and audio into a shared vector space, enabling the model to describe an image, caption a video or answer questions about visual content all within one architectural framework.
This convergence means the transformer blueprint has become the foundation of nearly every modern AI system. Whether it’s ChatGPT writing text, DALL·E generating images or Gemini integrating multiple modalities, they all share the same underlying logic: tokens, attention and embeddings.
The transformer isn’t just an NLP model; it’s a universal architecture for understanding and generating any kind of data.
Leadership takeaway
The transformer’s most profound breakthrough isn’t just technical — it’s architectural. It proved that intelligence could emerge from design — from systems that are distributed, parallel and context-aware.
For engineering leaders, understanding transformers isn’t about learning equations; it’s about recognizing a new principle of system design.
Architectures that listen, connect and adapt just like attention layers in a transformer consistently outperform those that process blindly.
Teams built the same way — context-rich, communicative and adaptive — become more intelligent over time.
The views expressed in this article are the author’s own and do not represent those of Amazon.
This article is published as part of the Foundry Expert Contributor Network.
Want to join?
Read More from This Article: Understanding transformers: What every leader should know about the architecture powering GenAI
Source: News