Data is the foundation of innovation, agility and competitive advantage in today’s digital economy. As technology and business leaders, your strategic initiatives, from AI-powered decision-making to predictive insights and personalized experiences, are all fueled by data. Yet, despite growing investments in advanced analytics and AI, organizations continue to grapple with a persistent and often underestimated challenge: poor data quality. Your role in addressing this challenge is crucial to the success of your organization.
Fragmented systems, inconsistent definitions, legacy infrastructure and manual workarounds introduce critical risks. These issues don’t just hinder next-gen analytics and AI; they erode trust, delay transformation and diminish business value. Data quality is no longer a back-office concern. It’s a strategic imperative that demands the focus of both technology and business leaders.
In this article, I am drawing from firsthand experience working with CIOs, CDOs, CTOs and transformation leaders across industries. I aim to outline pragmatic strategies to elevate data quality into an enterprise-wide capability. These strategies, such as investing in AI-powered cleansing tools and adopting federated governance models, not only address the current data quality challenges but also pave the way for improved decision-making, operational efficiency and customer satisfaction. Key recommendations include investing in AI-powered cleansing tools and adopting federated governance models that empower domains while ensuring enterprise alignment.
We also examine how centralized, hybrid and decentralized data architectures support scalable, trustworthy ecosystems. As data-centric AI, automated metadata management and privacy-aware data sharing mature, the opportunity to embed data quality into the enterprise’s core has never been more significant.
One thing is clear for leaders aiming to drive trusted AI, resilient operations and informed decisions at scale: transformation starts with data you can trust. As a leader, your commitment to data quality sets the tone for the entire organization, inspiring others to prioritize this crucial aspect of digital transformation.
Why data quality matters — and its impact on business
AI and analytics are transforming how businesses operate, compete and grow. However, even the most sophisticated models and platforms can be undone by a single point of failure: poor data quality. This challenge remains deceptively overlooked despite its profound impact on strategy and execution. The decisions you make, the strategies you implement and the growth of your organizations are all at risk if data quality is not addressed urgently.
Fragmented systems, inconsistent definitions, outdated architecture and manual processes contribute to a silent erosion of trust in data. When customer records are duplicated or incomplete, personalization fails. When financial data is inconsistent, reporting becomes unreliable. And when AI models are trained on flawed inputs, the resulting decisions — however automated — are fundamentally flawed.
The patterns are consistent across industries. Different teams define the same terms in diverse ways. Data is spread across disconnected tools and legacy systems. Business units manipulate spreadsheets in isolation, each introducing their own version of “truth.” These aren’t just operational inefficiencies; they are barriers to scale, innovation and performance.
In my experience, these issues rarely surface until something breaks. A cross-sell campaign underperforms because customer segmentation is misaligned. A compliance report is rejected because timestamps don’t match across systems. In financial services, mismatched definitions of “active account” or incomplete know-your-customers (KYC) data can distort risk models and stall customer onboarding. In healthcare, missing treatment data or inconsistent coding undermines clinical AI models and affects patient safety. In retail, poor product master data skews demand forecasts and disrupts fulfillment. In the public sector, fragmented citizen data impairs service delivery, delays benefits and leads to audit failures. These examples reflect not a technical gap but a data trust issue, and they are just a few instances of the pervasive impact of poor data quality across industries.
What makes this even more pressing is that responsibility for data quality is often unclear. As leaders in your organizations, it is crucial to define ownership and establish proactive governance. Without these, fixes are reactive — costly, manual and usually too late to prevent damage. Your proactive approach can prevent these issues from occurring in the first place.
Data quality must be embedded into how systems are designed, processes are governed and decisions are made. It’s not just about accuracy and confidence — confidence that your analytics are dependable, confidence that your AI can be trusted and confidence that your teams are aligned around a common truth.
Organizations that prioritize trusted data don’t just make better decisions. They create a foundation for lasting advantage.
Root causes of poor data quality
Vipin Jain
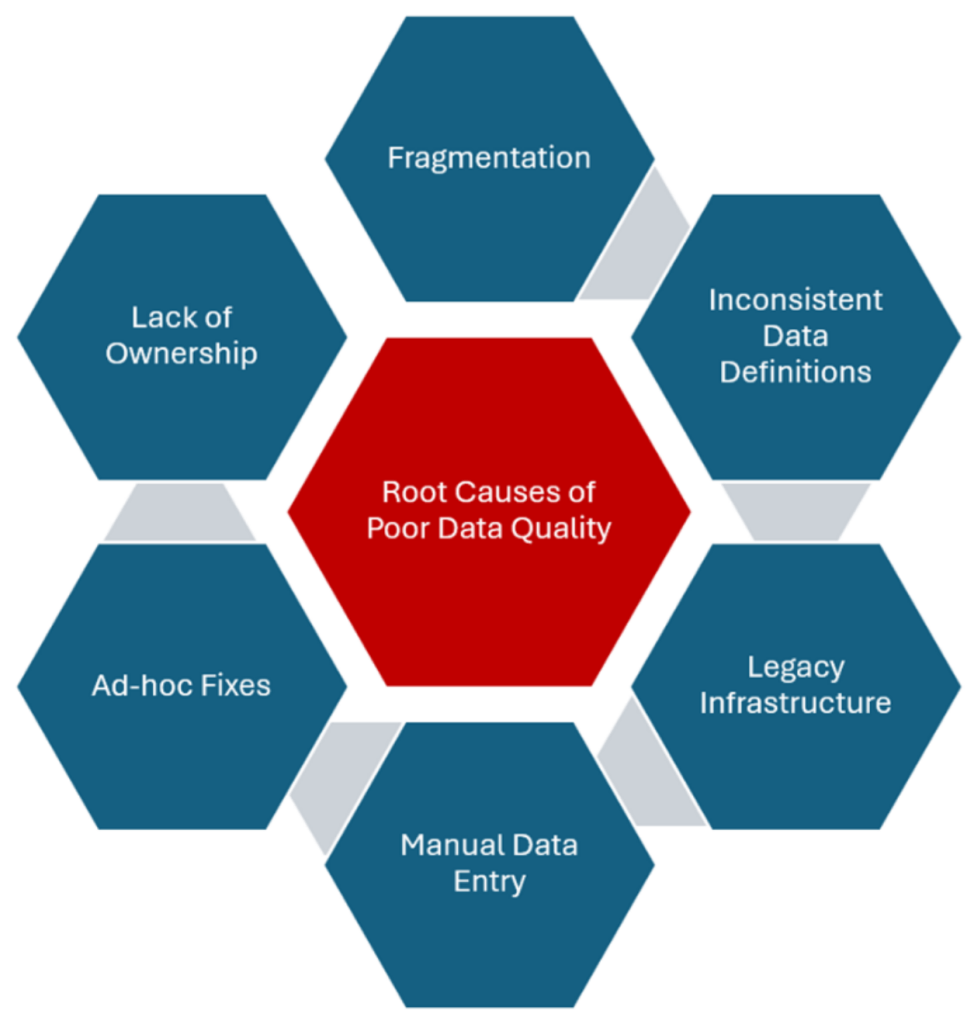
Despite broad awareness of its importance, data quality remains a persistent challenge. A lack of tools or intention doesn’t cause most issues — they stem from deep-rooted structural, cultural and operational weaknesses that are surprisingly common across industries.
- Fragmentation is one of the most widespread problems. Data lives across siloed systems — ERP, CRM, cloud platforms, spreadsheets — with little integration or consistency. I’ve seen teams struggle to reconcile information scattered across dozens of disconnected sources, each with its definitions and logic.
- Inconsistent business definitions are equally problematic. What one team considers a “customer,” another may classify as a lead or inactive account. These inconsistencies fuel reporting errors, undermine analytics and stall enterprise-wide alignment.
- Legacy infrastructure compounds these challenges. Outdated systems cannot enforce modern validation rules, automate cleansing or scale quality controls. Instead, organizations resort to manual workarounds — often managed by overburdened analysts or domain experts.
- Manual entries also introduce significant risks. When data quality depends on human vigilance without safeguards, errors multiply.
- Ad hoc fixes also introduce significant risks. Fixes happen reactively — usually after something has gone wrong — rather than being designed into workflows from the start.
- Lack of ownership is one of the most critical root causes. Data quality falls into a gray area between IT and business in many organizations. Without defined accountability or empowered stewards, issues persist and progress stalls.
Addressing these root causes requires more than technology — it involves clarity in governance, consistency in definitions and accountability across the enterprise. The organizations making real progress treat data quality not as a one-off fix but as an operational discipline that cuts across systems, teams and decisions.
From reactive fixes to embedded data quality
Vipin Jain
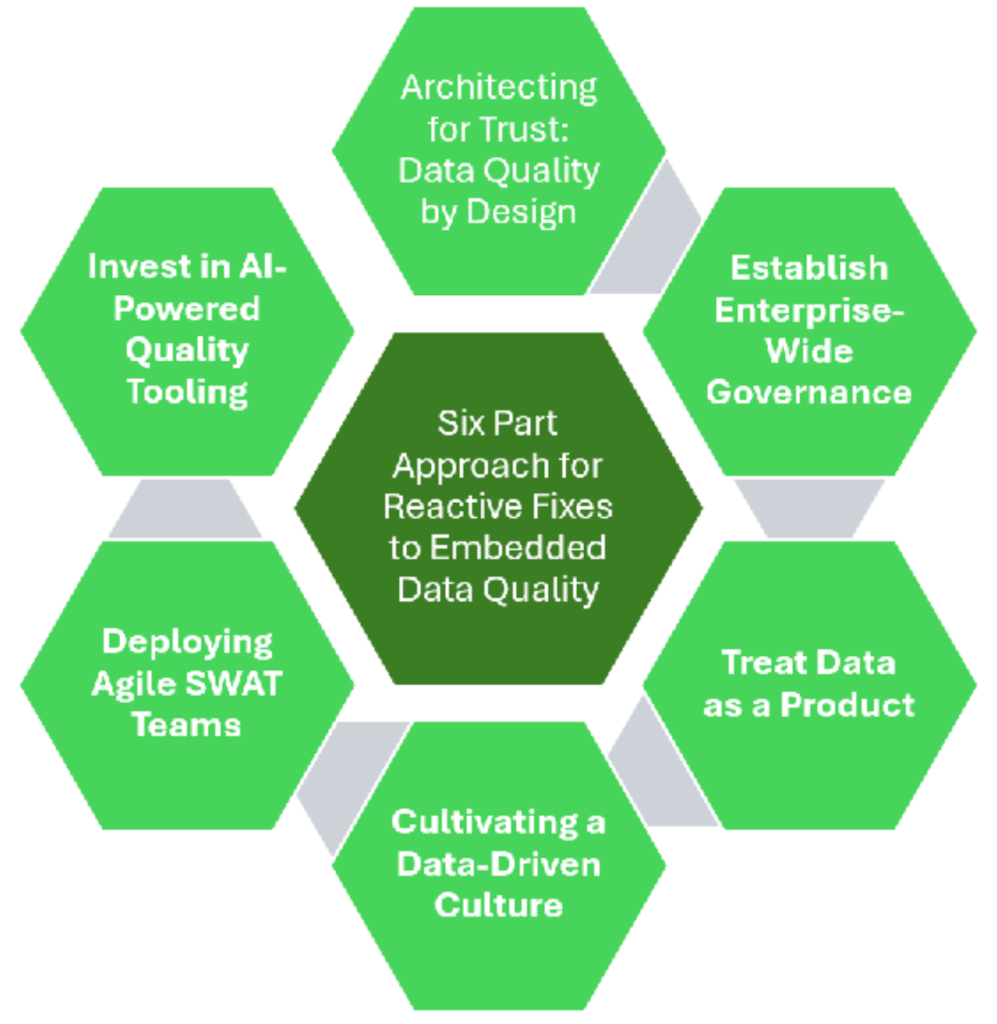
Breaking free from recurring data issues requires more than cleanup sprints — it demands an enterprise-wide shift toward proactive, intentional design. Data quality must be embedded into how data is structured, governed, measured and operationalized. Through transformation programs, I’ve found that organizations that institutionalize this mindset — starting with architectural design and extending to operational execution — build data resilience that scales with the business.
The following details a six-part approach that senior technology and business leaders can use to enable lasting data quality improvement.
1. Architecting for trust: data quality by design
Data architecture is the first and most fundamental layer where data quality can be engineered by design rather than corrected downstream. Choosing the right architecture isn’t just a technical decision; it’s a strategic one that affects integration, governance, agility and cost. Whether centralized or distributed, architecture shapes how data flows, how easily it can be trusted and how responsive systems are to change. As data volumes and use cases scale — especially with AI and real-time analytics — trust must be an architectural principle, not an afterthought.
Comparison of modern data architectures:
| Architecture | Definition | Strengths | Weaknesses | Best used when… |
|---|---|---|---|---|
| Data warehouse | Centralized, structured and curated data repository. | High consistency, regulatory alignment, strong for BI. | Inflexible schema, poor for unstructured or real-time data. | Compliance-heavy environments, enterprise reporting. |
| Data lake | Raw storage for all types of structured and unstructured data. | Low cost, flexibility, captures diverse data sources. | Easy to lose control, risk of becoming a “data swamp.” | Exploratory analytics, raw and diverse data types. |
| Lakehouse | Combines warehouse governance with lake flexibility. | Ideal for hybrid use cases, balances cost and structure. | Still maturing, may require modern skillsets. | Unified analytics, mixed workloads. |
| Data mesh | Domain-owned, decentralized architecture focused on data as a product. | Promotes ownership, agile, aligns IT and business. | Requires strong governance and cultural change. | Complex orgs with mature data capabilities. |
| Data fabric | Metadata-rich integration layer across distributed systems. | Real-time visibility, cross-system governance, hybrid/cloud friendly. | Implementation complexity, relies on robust metadata management. | Real-time integration across siloed or multi-cloud data. |
Architectural practices for built-in data quality
- Automate schema validation at source. Build data validation rules directly into ingestion layers so that insufficient data is stopped at the gate and not detected after damage is done.
- Embed end-to-end lineage tracking. Use lineage tooling to trace data from source to report. Understanding how data transforms and where it breaks is crucial for audibility and root-cause resolution.
- Deploy observability and monitoring pipelines. Embed observability into pipelines to detect anomalies, delays and drift in real time so that errors are flagged and fixed before affecting business decisions.
A well-architected data environment does more than store data. It sets the stage for governance, quality tooling and analytics, reducing complexity downstream. Organizations prioritizing architecture as a quality enabler see better scalability, faster insights and reduced firefighting.
2. Establish enterprise-wide governance
Even the best tools and architecture won’t prevent data quality degradation without governance. Governance connects policies to practice, aligning standards, roles and responsibilities. It ensures that everyone touching data is aligned around standard rules, definitions and accountability, essential for scaling data initiatives across departments, platforms and geographies. Effective governance doesn’t mean top-down control but federated accountability with the right balance of central policy and local empowerment.
Core governance actions
- Standardize enterprise data definitions. Create authoritative definitions for key business terms, such as “customer,” “revenue,” or “active account,” so teams speak the same language across reports, platforms and regions.
- Assign domain data stewards. Appoint accountable individuals within each domain to keep quality, approve changes and escalate issues. Data stewardship drives ownership and embeds trust locally.
- Create cross-functional data councils. Bring together IT, business, analytics and compliance leaders to guide priorities, resolve disputes and make shared decisions about quality, access and usage.
Robust governance ensures consistency without slowing teams down. It transforms data from “nobody’s job” to “everyone’s shared responsibility,” enabling controlled flexibility, sustained quality and regulatory confidence.
3. Treat data as a product
Data products are curated, maintained and governed assets built for consumption — just like any customer-facing system. Shifting to this mindset elevates data from a passive byproduct of systems to an actively managed, user-centric capability. Treating data as a product promotes accountability, quality and usability by design.
Key components of data product thinking
- Appointing a data product owner. Each domain (e.g., Customer, Product, Finance) needs a business-aligned owner responsible for availability, quality and roadmap evolution.
- Define quality SLAs and version control. Set performance expectations for timeliness, accuracy and completeness. Like software, data products should have versioning and changelogs to track evolution and impact.
- Publish metadata, documentation and use guidelines. Make it easy to discover, understand and use data through accessible catalogs and standardized documentation.
This mindset creates long-term accountability and lifecycle awareness. Data becomes a durable asset, built, improved and reused intentionally, helping teams scale insights faster and with greater trust.
4. Cultivating a data-driven culture
Building a data-driven culture is essential for organizations aiming to harness data for strategic advantage. This transformation involves several critical components:
- Executive sponsorship and visibility. Leadership must actively champion data initiatives, showing a commitment that permeates the organization. When executives prioritize data-driven decision-making, they signal its importance, fostering alignment across all levels.
- Data literacy and recognition. Empowering employees with the skills to interpret and use data is vital. Comprehensive training programs enhance data literacy, enabling informed decisions. Recognizing and rewarding data-centric achievements reinforces the value placed on analytical ability.
- Accountability and embedded SLAs. Establishing clear accountability ensures data integrity. Implementing Service Level Agreements (SLAs) for data quality and availability sets measurable standards, promoting responsibility and trust in data assets.
By focusing on these areas, organizations can cultivate a culture where data is integral to decision-making, driving innovation and competitive advantage.
5. Deploying agile SWAT teams
Rather than waiting for enterprise-wide overhauls, leading organizations use cross-functional “data SWAT” teams to drive rapid, targeted improvements. These teams focus on high-impact data issues, delivering measurable results in weeks instead of months by working close to the business.
Key principles of agile data SWAT teams
- Co-locate with business units. Place teams within departments to ensure real-world context and fast feedback loops between data engineers and business users.
- Prioritize and sprint on high-impact issues. Focus on pain points — broken pipelines, mismatched hierarchies and missing fields actively harming reports or AI models.
- Build quick wins, then scale. Iterate on success: stabilize one use case, implement preventative checks and redeploy to tackle the next challenge.
This agile, iterative approach shifts organizations from reactive cleanups to momentum — building interventions — faster, more focused and better aligned with business needs.
6. Invest in AI-powered quality tooling
AI and machine learning are transforming data quality — from profiling and anomaly detection to automated enrichment and impact tracing. These tools reduce manual burden while catching issues humans might miss, enabling proactive quality on a scale.
Capabilities of modern AI-driven data quality tools
- Detect, predict and suggest fixes automatically. Use machine learning models to detect schema drift, anomalies and duplication patterns and provide real-time recommended resolutions.
- Monitor continuously at scale. Run real-time checks across large pipelines to flag quality issues before propagating — minimizing downstream cleanup or decision delays.
- Automate lineage and impact analysis. Map how changes ripple across pipelines and reports to speed up root cause investigations and reduce compliance risk.
AI-powered tooling turns quality from a manual bottleneck into a strategic, scalable service, improving enterprise accuracy, transparency and responsiveness.
This isn’t just a best-practice checklist, it’s a new way of operating. When enterprises design trust, govern with clarity, manage data as a product, fix what matters quickly and automate quality assurance at scale, they embed trust into every system and process. That’s the foundation for competitive advantages, reliable analytics and ethical AI.
Data quality KPIs and maturity model
Integrating key performance indicators (KPIs) with a data quality maturity model enables organizations to assess and enhance their data management practices systematically. Below is a comprehensive table that outlines each maturity level, its characteristics, associated data quality KPIs and the expected values for these KPIs at each level:
| Maturity level | Characteristics | Relevant data quality KPIs and expected values |
|---|---|---|
| Level 1: Reactive | No formal strategy. Data issues are addressed only when problems arise. |
Completeness: Low (e.g., 60-70%) due to lack of standardized data entry processes. Accuracy: Low (e.g., 60-70%) as data is often outdated or incorrect. |
| Level 2: Tactical | Basic profiling tools implemented. Data stewards are assigned to critical systems. |
Completeness: Moderate (e.g., 70-80%) with improvements from initial profiling. Accuracy: Moderate (e.g., 70-80%) due to initial data cleansing efforts. Consistency: Low to Moderate (e.g., 65-75%) as data silos still exist. |
| Level 3: Proactive | Defined KPIs. Continuous measurement of data quality. Cross-functional collaboration. |
Completeness: High (e.g., 80-90%) with standardized data entry protocols. Accuracy: High (e.g., 80-90%) through regular validation against trusted sources. Consistency: Moderate to High (e.g., 75-85%) with efforts to align data across platforms. Timeliness: Moderate (e.g., data available 24-48 hours). |
| Level 4: Embedded | Data quality practices are integrated into product development and operational workflow. Proactive issue prevention. |
Completeness: Very High (e.g., 90-95%) due to embedded quality checks. Accuracy: Very High (e.g., 90-95%) with continuous monitoring. Consistency: High (e.g., 85-95%) as integration across systems is achieved. Timeliness: High (e.g., data available within 1-24 hours). |
| Level 5: Optimized | AI-assisted validation and predictive remediation. Organization-wide culture prioritizing trusted data. |
Completeness: Near Perfect (e.g., 95-100%) with automated data entry Validations. Accuracy: Near Perfect (e.g., 95-100%) through AI-driven anomaly detection. Consistency: Very High (e.g., 95-100%) with seamless data integration. Timeliness: Near Real Time (e.g., data available within minutes). Uniqueness: Very High (e.g., 95-100%) with advanced duplicate detection mechanisms. |
By understanding these maturity levels and associated KPIs, organizations can assess their current data quality practices and implement strategies to advance through the maturity model, ultimately achieving optimized data management and utilization.
Roadmap for CIOs/CDOs
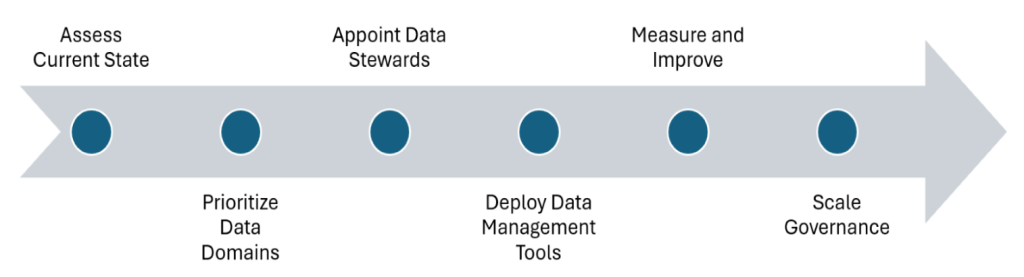
Establishing a robust data quality framework is essential for organizations that leverage data as a strategic asset. For CIOs and CDOs, a structured roadmap can guide data quality and governance enhancement. The following six-step approach provides a clear pathway:
Vipin Jain
- Assess current state. Comprehensively evaluate the organization’s data landscape. Utilize surveys, audits and profiling tools to find existing data assets, sources and flows, pinpointing areas plagued by inconsistencies, inaccuracies or redundancies. This diagnostic phase sets the foundation for targeted improvements.
- Prioritize data domains. Using insights from the assessment, focus on high-impact areas tied to business outcomes. Prioritizing data domains based on their significance to business goals and the severity of quality issues ensures the effective allocation of resources to first address the most critical data challenges.
- Appoint data stewards. Assign owners with authority and support for key data domains. Appointing data stewards establishes clear ownership and accountability, empowering individuals to oversee data quality initiatives, enforce governance policies and serve as contact points for data-related inquiries. This fosters a culture of responsibility and continuous improvement.
- Deploy data management tools. Select and integrate advanced data quality monitoring and remediation tools. Implementing these tools automates quality checks, monitors data integrity and facilitates remediation processes, enhancing efficiency and providing real-time insights into data health.
- Measure and improve. Track key performance indicators (KPIs) such as accuracy, completeness, consistency, timeliness and uniqueness. Regularly reviewing these metrics, publishing dashboards and iterating in sprints allows organizations to gauge progress, identify emerging issues and refine strategies accordingly.
- Scale governance. Expand data quality initiatives across additional domains with federated ownership. Integrating these initiatives into broader organizational processes should accompany ongoing training and communication to sustain momentum and embed data quality into the organizational culture.
By methodically following this roadmap, CIOs and CDOs can transform data quality from a technical concern into a strategic enabler, driving informed decision-making and competitive advantage.
Looking ahead
As organizations navigate the evolving data landscape, embracing advanced technologies is imperative to maintain a competitive edge. Key areas to focus on include:
- Self-healing pipelines. Implementing AI-driven workflows that autonomously detect and rectify errors ensures continuous data flow and minimizes downtime. These systems proactively identify anomalies and apply corrective measures without human intervention, enhancing operational efficiency.
- Edge data validation. Integrating real-time quality checks at the point of data generation ensures accuracy and consistency from the outset. This approach reduces the propagation of errors through data pipelines, leading to more reliable analytics and decision-making processes.
- Synthetic data. Utilizing AI-generated data to fill gaps and simulate rare events enables robust testing and model training without compromising sensitive information. Synthetic data provides a scalable solution for scenarios where accurate data is scarce, or privacy concerns are paramount.
- Data clean rooms. Establishing secure environments for sharing sensitive data across organizations facilitates collaborative analysis while maintaining strict privacy controls. These controlled settings enable multiple parties to derive insights from combined datasets without exposing underlying data, fostering innovation and compliance.
- Post-quantum readiness. Preparing for advancements in quantum computing involves transitioning to quantum-resistant encryption standards to safeguard data against emerging threats. Proactive assessment and upgrading of cryptographic infrastructures are essential to maintain data security in the quantum era.
By strategically investing in these areas, organizations can build resilient, future-ready data infrastructures that uphold trust and drive sustained success.
It’s time to prioritize data quality
High-quality data is the foundation of successful AI initiatives, directly influencing AI models’ performance, accuracy and reliability. Investing in advanced data management tools and fostering a culture of accountability are critical steps toward achieving data excellence. Implementing AI-driven data quality management can automatically identify and resolve inconsistencies in real time, enhancing efficiency and providing trustworthy insights.
Embedding trust in your data strategy requires integrating data quality practices into all business processes. Organizations can unlock transformative insights, streamline operations and enable innovative business models by treating data as a critical asset with non-negotiable attributes of quality, consistency and trustworthiness. Prioritizing data quality ensures that AI systems produce reliable outcomes, fostering trust and confidence among users.
As AI continues to reshape industries, leadership’s role in championing data quality has never been more vital. By leading the shift from reactive data cleanup to proactive data trust, organizations can position themselves to thrive in the data-driven economy of tomorrow. High-quality data allows AI models to learn from accurate patterns and make reliable predictions, translating to better organizational decision-making.
Vipin Jain, founder and chief architect of Transformation Enablers Inc., brings over 30 years of experience crafting execution-ready IT strategies and transformation roadmaps aligned with business goals while leveraging emerging technologies like AI. He has held executive roles at AIG, Merrill Lynch and Citicorp, where he led business and IT portfolio transformations. Vipin also led consulting practices at Accenture, Microsoft and HPE, advising Fortune 100 firms and U.S. federal agencies. He is currently a senior advisor at WVE.
This article was made possible by our partnership with the IASA Chief Architect Forum. The CAF’s purpose is to test, challenge and support the art and science of Business Technology Architecture and its evolution over time as well as grow the influence and leadership of chief architects both inside and outside the profession. The CAF is a leadership community of the IASA, the leading non-profit professional association for business technology architects.
Read More from This Article: Data’s dark secret: Why poor quality cripples AI and growth
Source: News