When custom pipelines start to crack
In the early stages of building a data platform, it’s common to patch together ingestion workflows by hand — scripting one-off jobs, customizing transformations per customer and relying on tribal knowledge to keep things running. It works…until it doesn’t.
At a fast-scaling healthcare technology company, our customer base grew faster than our data infrastructure. What once felt nimble started to feel fragile: pipelines failed silently, onboardings dragged out for weeks and debugging meant diving into a maze of logs.
We realized we weren’t just struggling with tools — we were facing architectural debt.
That’s when we hit pause, audited our data platform and launched a full evaluation of extract, transform and load (ETL) tooling with one goal: to modernize our ingestion stack for scale.
This is a practical story of what worked, what didn’t and how we built an evaluation rubric grounded in operational reality — not just features.
The tipping point: From flexibility to friction
Our biggest pain point wasn’t data volume — it was the growing burden of custom pipelines and bespoke ingestion logic. Initially, our pipelines were tailored to each customer: one-off joins, manual schema patches, custom workflows. But as we grew, this flexibility turned into fragmentation:
- Schema inconsistency caused brittle transformations
- Manual edge-case handling created high onboarding costs
- Lack of modularity meant rework for every new customer
- No centralized observability made failures hard to detect and debug
The result? Fragile infrastructure and slower customer onboarding, both of which blocked growth.
We didn’t just want to fix today’s pain. We wanted to build a data platform that could serve the entire company. That meant supporting small workloads today, but also being able to ingest, transform and monitor data from all teams as the company scaled. And critically, we wanted a solution where costs scaled with usage, not a flat-rate platform that became wasteful or unaffordable at lower loads.
Defining requirements: What we actually needed
Rather than chasing hype, we sat down to define what our platform needed to do, functionally and culturally.
Here were our top priorities:
1. Schema validation at the edge
Before any data enters our system, we wanted strong contracts: expected fields, types and structure validated upfront. This prevents garbage-in, garbage-out issues and avoids failures downstream.
2. Modular, reusable transformations
Instead of rewriting business logic per customer, we needed to break ingestion into reusable modules — join, enrich, validate, normalize. These could then be chained based on customer configs.
3. Observable by default
Pipeline health shouldn’t be an afterthought. We wanted metrics, lineage and data quality checks built in — visible to both engineers and customer success teams.
4. Low-friction developer experience
Our team included data engineers, analytics engineers and backend devs. The ideal platform needed to support multiple personas, with accessible debugging and local dev workflows.
5. Cost and maintainability
We weren’t optimizing for high throughput — we were optimizing for leverage. We needed a platform that would scale with us, keeping cloud costs proportional to data volumes while remaining maintainable for a small team. The ideal tool had to be cost-efficient at low volumes, but robust enough to support high volumes in the future.
And above all, the platform had to fit the size of our team. With a lean data engineering group, we couldn’t afford to spread ourselves thin across multiple tools.
Evaluating the options: A real-world shortlist
We looked at six different platforms, spanning open-source, low-code and enterprise options:
Databricks
Great for teams already invested in Spark and Delta Lake. Offers strong support for large-scale transformations and tiered architectures (bronze/silver/gold).
- Offers strong notebook integration and robust compute scaling
- Natively supports Delta tables and streaming workloads
- Can be a heavier lift for teams unfamiliar with Spark
- Monitoring requires either Unity Catalog or custom setup
Mage.ai
A newer entrant focused on developer-friendly pipelines with metadata-first design.
- Provides a simple UI and Python-first configuration
- Includes built-in lineage tracking and scheduling
- Lacks the mature connector ecosystem of older platforms
- Still evolving around deployment and enterprise features
AWS Glue
Serverless, scalable and tightly integrated with the AWS ecosystem.
- Cost-effective for batch workloads with moderate frequency
- Supports auto-crawling and cataloging via Glue Data Catalog
- Developer experience can be frustrating, with limited debugging support
- Difficult to inspect job logic once deployed
Airflow
Popular orchestrator, especially for Python-native teams.
- Flexible and battle-tested, supported by a large community
- Can integrate with any backend logic or custom code
- Not an ETL engine itself; compute and observability must be added
- Flexibility can lead to pipeline sprawl without standards
Boomi/Rivery
Low-code integration tool with drag-and-drop interfaces.
- Quick time-to-value for basic integrations
- Accessible for business and non-technical users
- Limited capabilities for complex or nested transformations
- Not designed for high-volume or semi-structured data
DBT
An industry standard for modeling transformations inside the data warehouse.
- Encourages modular, testable SQL-based transformations
- Excellent documentation and lineage tracking
- Not suited for ingestion or unstructured data
- Requires an existing warehouse environment
Lessons learned: One platform, real progress
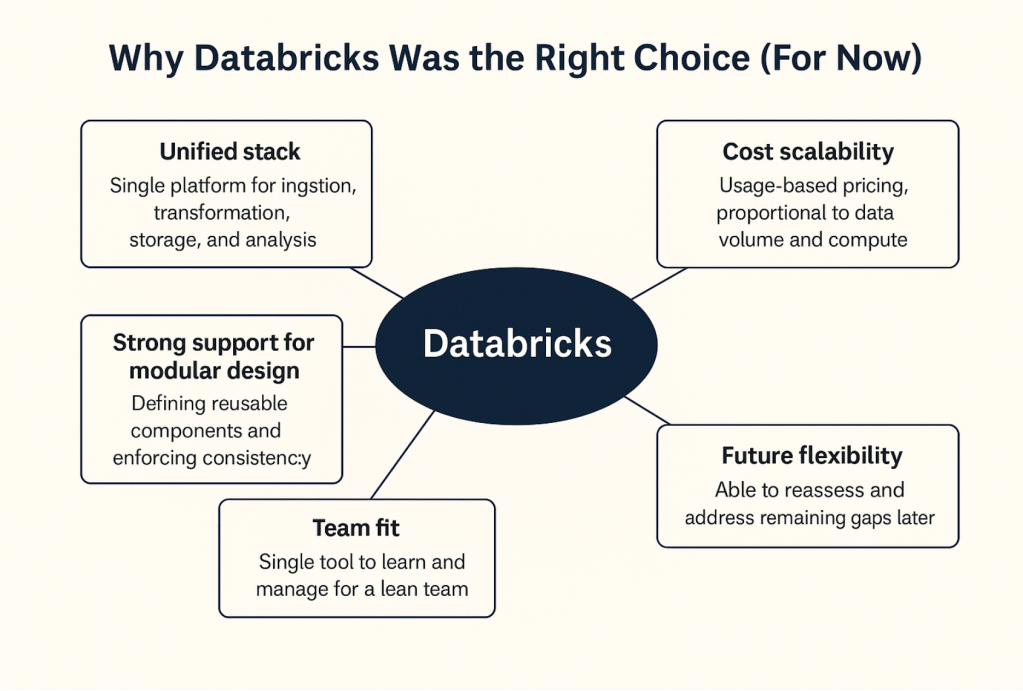
After evaluating all six, we ultimately finalized on Databricks to run our end-to-end ingestion — from raw input to transformation, observability and lineage. It didn’t solve all of our problems, but it solved about 60% of them — and that was a meaningful leap. For a lean data team of five, consolidating into a single, flexible platform gave us the clarity, maintainability and leverage we needed.
Akrita Argawal
In an ideal world, we might have chosen two tools — perhaps one for ingestion and one for transformation — to get best-in-class capabilities across the board. But with limited time and zero integration experience between those tools and our stack, that wasn’t practical. We had to be smart. We chose a tool that helped us move faster today, knowing it wouldn’t be perfect.
With that 60% productivity gain, we’re not done. We’ll revisit the gaps. Maybe we’ll find that a second tool fits well later. Or maybe we’ll discover that the remaining problems require something custom. That brings us to the inevitable question in every engineering roadmap: buy vs. build.
Final thought: Be pragmatic, and build for the next 50 customers
This is the guidance I’d offer to any team evaluating tools today: be pragmatic. Evaluate your needs clearly, keep an eye on the future and identify the top three problems you’re trying to solve. Accept up front that no tool will solve 100% of your problems.
Be honest about your strengths. For us, it was the lack of data scale and lack of urgent deliverables — we had room to design. Be equally honest about your weaknesses. For us, it was the prevalence of custom ingestion code and the constraints of a lean team. Those shaped what we could reasonably adopt, integrate and maintain.
Choosing an ETL platform isn’t just a technical decision. It’s a reflection of how your team builds, ships and evolves. If your current stack feels like duct tape, it might be time to pause and ask: what happens when we double again?
Because the right ETL platform doesn’t just process data — it creates momentum. And sometimes, real progress means choosing the best imperfect tool today, so you can move fast enough to make smarter decisions tomorrow.
This article is published as part of the Foundry Expert Contributor Network.
Want to join?
Read More from This Article: Modernizing data ingestion: How to choose the right ETL platform for scale
Source: News