In today’s economy, as the saying goes, data is the new gold — a valuable asset from a financial standpoint. However, from a company’s existential perspective, there’s an even more fitting analogy. We are all familiar with the theory of evolution, where the Earth began as a rocky planet and eventually teemed with life. A similar transformation has occurred with data. More than 20 years ago, data within organizations was like scattered rocks on early Earth. It was not “alive” because the business knowledge required to turn data into value was confined to individuals’ minds, Excel sheets or lost in analog signals.
Digital transformation started creating a digital presence of everything we do in our lives, and artificial intelligence (AI) and machine learning (ML) advancements in the past decade dramatically altered the data landscape. We are now deciphering rules from patterns in data, embedding business knowledge into ML models, and soon, AI agents will leverage this data to make decisions on behalf of companies. Data is now “alive” like a living organism, flowing through the company’s veins in the form of ingestion, curation and product output. This organism is the cornerstone of a company’s competitive advantage, necessitating careful and responsible nurturing and management.
To succeed in today’s landscape, every company — small, mid-sized or large — must embrace a data-centric mindset. This article proposes a methodology for organizations to implement a modern data management function that can be tailored to meet their unique needs. By “modern”, I refer to an engineering-driven methodology that fully capitalizes on automation and software engineering best practices. This approach is repeatable, minimizes dependence on manual controls, harnesses technology and AI for data management and integrates seamlessly into the digital product development process. The proposed model illustrates the data management practice through five functional pillars: Data platform; data engineering; analytics and reporting; data science and AI; and data governance.
Manish Limaye
Pillar #1: Data platform
The data platform pillar comprises tools, frameworks and processing and hosting technologies that enable an organization to process large volumes of data, both in batch and streaming modes. Organizations must decide on their hosting provider, whether it be an on-prem setup, cloud solutions like AWS, GCP, Azure or specialized data platform providers such as Snowflake and Databricks. They must also select the data processing frameworks — such as Spark, Beam or SQL-based processing — and choose tools for ML.
Based on business needs and the nature of the data, raw vs structured, organizations should determine whether to set up a data warehouse, a Lakehouse or consider a data fabric technology. The choice of vendors should align with the broader cloud or on-premises strategy. For example, if a company has chosen AWS as its preferred cloud provider and is committed to primarily operating within AWS, it makes sense to utilize the AWS data platform. Similarly, there is a case for Snowflake, Cloudera or other platforms, depending on the company’s overarching technology strategy.
However, I am not in favor of assembling numerous tools in pursuit of the elusive “best of breed” dream, as integrating these tools is excessively time-consuming, and technology evolves too rapidly for DIY integration to keep up. Furthermore, generally speaking, data should not be split across multiple databases on different cloud providers to achieve cloud neutrality. Not my original quote, but a cardinal sin of cloud-native data architecture is copying data from one location to another. That’s free money given to cloud providers and creates significant issues in end-to-end value generation.
While technology decisions are crucial, the true purpose of the Data Platform pillar is to build a foundation for creating business value. Lack of focus on the time value of the money and business value can turn Data Platform selection into a high school science project, so watch out for that. This pillar is inherently engineering-focused, and although it may initially start with manual setup, companies must transition to fully automated mindsets. Operational errors because of manual management of data platforms can be extremely costly in the long run.
Pillar #2: Data engineering
This function is responsible for transforming raw data into curated data products. Raw data is ingested, transformed and curated for a specific purpose using tools and frameworks provided by Data Platforms. Unlike the technology-focused Data Platform pillar, Data Engineering concentrates on building distributed parallel data pipelines with embedded business rules. It is crucial to remember that business needs should drive the pipeline configuration, not the other way around. For example, if preserving the order of events is essential for business needs, the appropriate batch, micro-batch or streaming configuration must be implemented to meet these requirements.
Another key area involves managing the operational health of data pipelines, with an even greater emphasis on monitoring the quality of the data flowing through the pipeline. Poor-quality data is as detrimental as a pipeline outage, and perhaps more, as it can lead to bad decisions and provide harmful information to customers. The field of data observability has experienced substantial growth recently, offering numerous commercial tools on the market or the option to build a DIY solution using open-source components. The most challenging aspect is setting the thresholds for data quality issue alerts, as real-world data is too dynamic for static thresholds to be effective. Implementing ML capabilities can help find the right thresholds. While it’s acceptable to start with manually set thresholds, the ultimate goal should be to automate them with self-learning mechanisms.
Finally, it is important to emphasize the “Engineering” aspect of this pillar. Just because the work is data-centric or SQL-heavy does not warrant a free pass. Every SQL query, script and data movement configuration must be treated as code, adhering to modern software development methodologies and following DevOps and SRE best practices.
Pillar #3: Analytics and reporting
This pillar represents the most traditional aspect of data management, encompassing both descriptive and diagnostic analytics capabilities. They generally fall into two broad categories:
- Fixed, canned or standard reports
- Ad hoc or individual use reports
Smaller companies with limited data can manage this pillar without extensive automated engineering discipline. However, mid and large-sized companies need to build sophisticated self-service reporting platforms on top of curated datasets within their data warehouse or Lakehouse.
The data platform function will set up the reporting and visualization tools, while the data engineering function will centralize the curated data. However, the analytics/reporting function needs to drive the organization of the reports and self-service analytics. It also needs to champion the democratization of data by ensuring the data catalog contains meaningful, reliable information and is coupled with proper access controls.
One of the most challenging aspects of business analytics is creating a consistent set of data definitions to ensure reports do not produce conflicting or unreliable information. The introduction of generative AI (genAI) and the rise of natural language data analytics will exacerbate this problem. Consequently, the concept of the semantic layer has gained considerable traction and needs to be considered in a mature setup.
The degree of engineering discipline required in this pillar correlates with the reports’ criticality. The higher the criticality and sensitivity to data downtime, the more engineering and automation are needed.
Pillar #4: Data science and AI
This pillar primarily encompasses the predictive and prescriptive aspects of analytics. Historically, this pillar was part of analytics and reporting, and it remains so in many cases. However, I deliberately separate it out because the output of this pillar, i.e., AI/ML models, now integrates into customer-facing products and services that must be operated like any other technology product. This marks a significant change in the industry and necessitates a deep engineering-centric approach to ML and AI.
Establishing this pillar requires data science, ML and AI skills. Equally important are MLOps skills to establish engineering discipline, and the presence of architects who can connect the dots end-to-end, covering business requirements, model development, model deployment and model monitoring. Without this setup, there is a risk of building models that are too slow to respond to customers, exhibit training-serving skew over time and potentially harm customers due to lack of production model monitoring. If a model encounters an issue in production, it is better to return an error to customers rather than provide incorrect data. This level of rigor demands strong engineering discipline and operational maturity.
However, there is good news for smaller companies. Data science was previously the domain of tech-savvy organizations due to the technical expertise required to build models from scratch. Advances in concepts such as data-centric AI, genAI and the availability of open-source and commercial AI models are shifting the AI equation from “in-house build” to “buy/reuse.” This development will make it easier for smaller organizations to start incorporating AI/ML capabilities.
Pillar #5: Data governance
We need a new term for data governance, as it often gets conflated with corporate or IT governance, which typically implies a governing body overseeing others’ work to ensure compliance with company policies. Historically, data governance operated similarly, with data governance leaders overseeing and approving the activities of other teams due to the separation between operational and analytical data. That made sense when the scope of data governance was limited only to analytical systems, and operational/transactional systems operated separately.
However, this landscape is rapidly evolving. Traditional data governance structures remain necessary but are no longer sufficient in an environment where valuable data permeates almost every aspect of the company including transactional systems. Modern data governance must create an ecosystem that ensures data is in the right condition everywhere, consistently accurate, secure, accessible to the right people and meeting compliance obligations across both operational and analytical systems. Such widespread governance requires well-defined automated controls and guidance, fully integrated into the product development lifecycle.
For example, if a data governance policy mandates describing data schema in a catalog with controls like constraints and min/max values, this step must be part of the automated software development life cycle — ensuring the system checks for a valid schema during deployment. Cybersecurity underwent a similar evolution over the past 20 years. Remember when securing systems was solely the responsibility of a few cybersecurity professionals, disconnected from the software development lifecycle? Now, mature organizations implement cybersecurity broadly using DevSecOps practices. Data governance needs to follow a similar path, transitioning from policy documents and confluence pages to data policy as code. Ensuring that data is in the right condition is everyone’s responsibility, and the data governance ecosystem must enable this through automation.
Establishing federated data governance also requires aligning incentives between operational and analytical teams and will occur once everyone realizes that incorrect data can harm customers and pose reputational risks for the company. This issue will be exacerbated by the future use of AI agents making decisions on behalf of companies based on data. Therefore, my top recommendation is to enhance data governance with a robust engineering discipline.
A new type of engineering-centric data organization
Over the past decade, advancements in AI and ML have transformed data management from a back-office reporting and governance function into a significant competitive advantage. AI/ML models now power customer-facing products with sub-second response times. This shift necessitates a new type of engineering-infused data organization, as described by the five pillars in this article.
Most organizations new to data management will initially focus on streamlining business operations for operational efficiencies. However, as they mature, the focus will shift towards new business initiatives and revenue growth opportunities. While the diagram in the introduction sections depicts all pillars as equally sized circles, in reality, investment and effort will resemble a spider chart diagram, with not all areas requiring equal attention at all times.
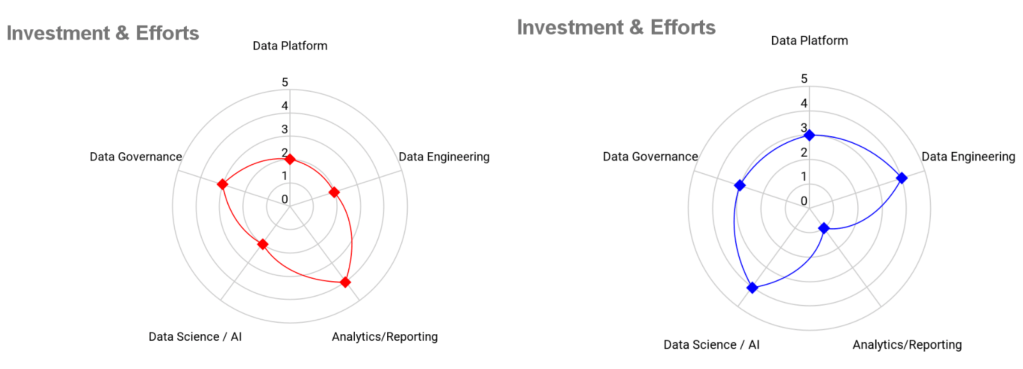
These figures show example investments on a scale of 0-5 for analytics/reporting-focused investments (left, in red) and data science-focused investments (right, in blue).
Manish Limaye
From an organizational reporting perspective, a smaller company can consolidate all five functions under one leader. A mid-sized company might combine the data platform and engineering functions under one leader, with the other three functions under another. A large, highly regulated company will likely distribute the five pillars among multiple leaders.
Although the scale, scope and size of the data function will vary across companies, one thing is certain: Data is omnipresent in the digital world. That customer service phone call taken by your agent is not an analog signal anymore; it is digital data that provides crucial insights into customer pain points and service quality. Hence, every company must think like a data company, set up a proper data management capability and leverage data as a competitive advantage.
Manish Limaye is a highly accomplished data and technology leader with more than 30 years of experience in IT and business transformation in the fintech and travel industries. As the chief architect and head of data engineering at Equifax’s USIS business unit, he drove the technology strategy and ran a large data engineering organization to completely transform the company. Prior to Equifax, Manish led the global platform architecture and shared services group for Travelport, where he brought hybrid cloud and big data platforms to the company. He is currently a technology advisor to multiple startups and mid-size companies.
This article was made possible by our partnership with the IASA Chief Architect Forum. The CAF’s purpose is to test, challenge and support the art and science of Business Technology Architecture and its evolution over time as well as grow the influence and leadership of chief architects both inside and outside the profession. The CAF is a leadership community of the IASA, the leading non-profit professional association for business technology architects.
Read More from This Article: The future of data: A 5-pillar approach to modern data management
Source: News